
Beitrag von Benjamin Aunkofer (DATANOMIQ GmbH)
Automatisierung der Maschinenüberwachung, -konfiguration und Qualitätssicherung mit maschinellem Lernen aus dem Bereich der Künstlichen Intelligenz
Mit der Dampfmaschine und der Automatisierung von einfachen mechanischen Arbeitsschritten über Zahnräder begann die erste industrielle Revolution. Mit der Elektrotechnik und dem Fließband die zweite und mit der Maschinen-Programmierung und -Simulation wurde die dritte industrielle Revolution eingeleitet. Heute steht uns die vierte industrielle Revolution mit den Möglichkeiten der Künstlichen Intelligenz nicht nur bevor – es liegt in unserer Hand, die Industrie 4.0 nun direkt anzugehen.
Automatisierung mit Künstlicher Intelligenz im Sinne der Industrie 4.0
Die vierte industrielle Revolution beschreibt die Vision der sich selbst optimierenden Produktion und fußt auf zwei Hauptkomponenten, die diese Selbstkonfiguration ermöglichen sollen. Zum einen auf der konsequenten Maschinenvernetzung untereinander, zu allen IT-Systemplattformen bis hin zu einzelnen Betriebsmitteln – dieser Teil ist immer noch Bestandteil der Digitalisierung, die bereits mit der dritten industriellen Revolution und der Einführung von ERP- und PDM-Systemen begonnen hatte. Zum anderen fußt die Industrie 4.0 auf der Nutzung der durch die Digitalisierung entstehenden Daten über den Einsatz von Machine Learning. Dabei handelt es sich um eine Technologie aus der Informatik, die heute bereits viele Tätigkeiten der Produktionsplanung, -steuerung und -überwachung übernehmen, mindestens jedoch ein hilfreiches Assistenzsystem darstellen kann.
Deep Learning – Teilbereich der künstlichen Intelligenz
Maschinelles Lernen (ML) ist eine Sammlung von mathematischen Methoden der Mustererkennung. Diese Methoden erkennen Muster beispielsweise durch die bestmögliche Zerlegung von Datenbeständen in hierarchische Strukturen (Entscheidungsbäume). Auch werden über Vektoren Ähnlichkeiten zwischen Datensätzen ermittelt und daraus trainiert oder untrainiert Muster erschlossen. Deep Learning (DL) ist eine Disziplin des maschinellen Lernens unter Einsatz von künstlichen neuronalen Netzen. Während die Ideen für Entscheidungsbäume, k-nN oder k-Means aus einer gewissen mathematischen Logik heraus entwickelt wurden, gibt es für künstliche neuronale Netze ein Vorbild aus der Natur: Biologische neuronale Netze.
Es gibt viele Topologien künstlicher neuronaler Netze, jedoch basieren alle auf einer gemeinsamen Grundlogik: Ein Eingabe-Vektor (eine Reihe von Dimensionen) stellt eine erste Schicht dar, die über weitere Schichten mit sogenannten Neuronen erweitert oder reduziert und über Gewichtungen abstrahiert wird, bis eine Ausgabeschicht erreicht wird, die einen Ausgabe-Vektor erzeugt. Ein Ausgabevektor ist ein Ergebnis-Schlüssel, der beispielsweise eine bestimmte Klasse ausweist: z. B. ein Maschinendefekt oder kein Maschinendefekt. Jedes der Neuronen ist eine kleine Schranke, die bei einem bestimmten Input „feuert“, also ein Signal gibt. Neuronen der ersten Schicht feuern abhängig von dem Input, Neuronen der weiteren Schichten abhängig von ihrem Input, der gleichzeitig der Output der vergangenen Schichten ist. Durch ein Training werden die Gewichte zwischen den Neuronen so angepasst, dass bestimmte Eingabe-Muster (z. B. Fotos von Werkstücken) die Neuronen „feuern“ lassen, dass auch die Neuronen der folgenden Schichten so „feuern“, dass die letzte Neuronen-Schicht immer zu einem bestimmten Ausgabe-Muster führt, das der jeweilig korrekten Klasse zugeordnet wird (z. B. “die Oberfläche des Werkstücks weißt einen Fehler auf”).
Der Vorteil von künstlichen neuronalen Netzen ist die sehr tiefgehende Abstraktion von Zusammenhängen zwischen Eingabe-Daten und zwischen den abstrahierten Neuronen-Werten mit den Ausgabe-Daten. Dies geschieht über mehrere Schichten (Layer) der Netze, die durch Abstraktion der Beziehung zwischen Eingabedaten und historischer Ergebnisse sehr spezielle Probleme lösen können. Aus diesen Tatsachen leitet sich der übergeordnete Name ab: Deep Learning
Deep Learning kommt dann zum Einsatz, wenn andere maschinelle Lernverfahren an Grenzen stoßen und auch dann, wenn auf eine separate Vorauswahl geeigneter Eingabedaten (das sogenannte Feature Engineering) verzichtet werden muss, denn neuronale Netze können über mehrere Schichten viele Eingabe-Dimensionen von selbst auf die Attribute reduzieren, die für die korrekte Bestimmung der Ausgabe notwendig sind.
Maschinenüberwachung mit Deep Learning
Künstliche neuronale Netze entwickeln Gewichtungsmodelle zwischen Eingabe- und Ausgabedaten. Dieses Prinzip kann – angewendet auf Maschinendaten – dazu genutzt werden, Frühwarnsysteme für fehlerhafte oder nicht optimale Produktionsläufe zu erstellen. Die Maschinen- und Produktionsmetadaten werden als x-Variablen zusammen mit den historisierten y-Werten dem Trainingsverfahren des künstlichen neuronalen Netzes zugeführt. Über die Trainingsprozedur entsteht ein Modell, dass die Zusammenhänge zwischen x und y beschreibt. Die resultierenden Zusammenhangsmodelle werden als Prädiktionsmodelle eingesetzt.
Der meistverbreitete Anwendungsfall für derartige Prädiktionsmodelle ist unter dem Begriff Predictive Maintenance bekannt, die prädiktive Erkennung von Instandhaltungsbedarfen. Diese Prädiktion wird durch ein Training mit Sensordaten (x) und Maschinenzuständen (y) ermöglicht. Jedoch sind auch andere Anwendungszwecke möglich, wie beispielsweise die Vorhersage der Energieeffizienz, der Output-Quantität oder -Qualität.
Zum Einsatz kommen zur Maschinenüberwachung Multi-Layer-Perzeptron-Netze (MLP), das sind solche mit vollständig vernetzten Neuronen zwischen den Schichten. Werden Neuronen auch quer-vernetzt oder mit vorherigen Schichten rückgekoppelt, sprechen wir hingegen vom rekurrenten künstlichen neuronalen Netz (RNN). Ein RNN ermöglicht die bessere Berücksichtigung von sequenziellen Abläufen bzw. der zeitlichen Komponente der Eingabedaten.
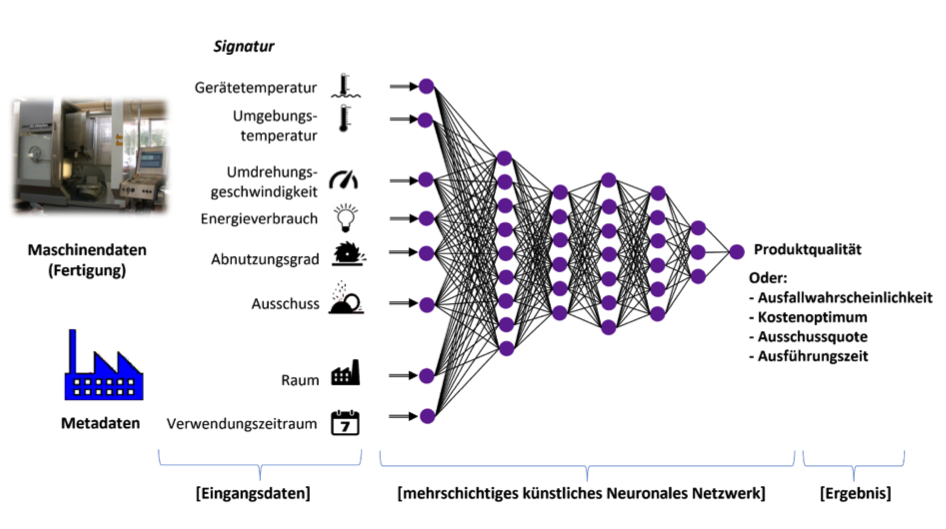
Abbildung 1 – Eine vereinfachte Illustration eines MLP-Netzes zur Modellentwicklung für die Prädiktion von Maschinen-Zuständen oder Fertigungsergebnissen.
Voraussetzungen und Wirkung von Deep Learning in der Produktion
In der Praxis arbeiten Maschinenhersteller längst an Predictive Maintenance als integratives System für ihre Werkzeugmaschinen und Fahrzeuge. Herausforderungen stellen in der Praxis jedoch ältere Anlagen sowie ganze Fertigungsinseln und -linien, bestehend aus mehreren Maschinen, dar, die nicht auf dem aktuellen Stand der Technik sind und auch nicht von einem einzigen Hersteller abgedeckt werden. Die Voraussetzungen für den Einsatz von Deep Learning sind Daten-Historien über die Zustände der Maschinen und Anlagen. Ist diese Historie nicht vorhanden, muss sie erst noch erhoben werden. Dies heißt jedoch nicht, dass die Data Science im Falle kürzerer Datenhistorien nicht schon Methoden zur Erkennung von Ausfallpotenzialen parat hält, denn über Methoden der Anomalie-Erkennung lassen sich Muster in Maschinenabläufen aufzeigen, die auf Instandhaltungsbedarfe oder auch auf Schwankungen in der Output-Qualität oder -Effizienz aufmerksam machen.
Aus der Erfahrung heraus können damit nicht nur reibungslosere Prozesse und somit geringere Durchlaufzeiten realisieren lassen, auch sind Kosteneinsparungen durch Wartungsvertragsoptimierung und Ausfallvermeidung im zweistelligen Prozentbereich möglich.
Über den Autor
Benjamin Aunkofer führt über die DATANOMIQ GmbH mehrere Teams von Datenexperten und befasst sich mit Projekten rund um Business Intelligence, Process Mining und Data Science. Machine Learning und Deep Learning spielen dabei immer wieder eine Kernrolle in Projekten für Kunden und sind Bestandteil seiner Lehre an Hochschulen oder in Trainings für Unternehmen.

